Пагинация на PHP для большого количества записей
Всем привет. В прошлом уроке мы рассмотрели пример простой пагинации, которая отлично работает при относительно небольшом количестве записей. Если же их становится много, мы столкнемся с проблемами.
Чтобы не делать всё с нуля я предлагаю доработать пагинацию, реализованную в прошлом уроке. Стяните проект с гитхаба и сделайте чекаут на вот этот коммит.
Чтобы обозначить проблемы, давайте напишем скрипт, который добавит в нашу базу 1 млн статей.
create_many_articles.php
<?php
spl_autoload_register(function (string $className) {
require_once __DIR__ . '/src/' . str_replace('\\', '/', $className) . '.php';
});
$db = \MyProject\Services\Db::getInstance();
$query = '';
for ($i = 1; $i <= 1000000; $i++) {
$query .= sprintf(
'INSERT INTO articles (`author_id`, `name`, `text`) VALUES (1, \'%s\', \'%s\');',
'Статья #' . $i,
'Текст статьи ' . $i
);
if ($i % 1000 === 0) {
$db->query($query);
$query = '';
echo $i . PHP_EOL;
}
}Запускаем его командой:
php create_many_articles.phpИ идём пить кофе. После завершения работы скрипта заходим на главную страницу нашего блога http://myproject.loc/
Как видим, у нас появилось довольно большое число страниц, которое просто разрывает наш шаблончик. Не знаю как у вас, а у меня вкладка в браузере просто-напросто зависла.

Давайте сделаем пагинацию в стиле туда-сюда. Для этого в экшене \MyProject\Controllers\MainController::page() передадим в шаблон 2 ссылки на предыдущую и следующую страницы.
public function page(int $pageNum)
{
$pagesCount = Article::getPagesCount(5);
$this->view->renderHtml('main/main.php', [
'articles' => Article::getPage($pageNum, 5),
'previousPageLink' => $pageNum > 1
? '/' . ($pageNum - 1)
: null,
'nextPageLink' => $pageNum < $pagesCount
? '/' . ($pageNum + 1)
: null
]);
}А в шаблоне выведем эти ссылки.
myproject.loc/templates/main/main.php
<div style="text-align: center">
<?php if ($previousPageLink !== null): ?>
<a href="<?= $previousPageLink ?>">< Туда</a>
<?php else: ?>
<span style="color: grey">< Туда</span>
<?php endif; ?>
<?php if ($nextPageLink !== null): ?>
<a href="<?= $nextPageLink ?>">Сюда ></a>
<?php else: ?>
<span style="color: grey">Сюда ></span>
<?php endif; ?>
</div>Любуемся аккуратным пагинатором.

Давайте теперь посмотрим на время генерации страницы. Для этого обернем код в index.php в следующие строки:
<?php
$startTime = microtime(true);
// тут весь остальной код
printf('<div style="text-align: center; padding: 5px">Время генерации страницы: %f</div>', $endTime - $startTime );Обновим первую страницу блога. У меня время генерации заняло 0.258032 секунды.

А теперь давайте откроем последнюю страницу блога - http://myproject.loc/200000
Время генерации страницы: 1.045724
Вот это да! Разница почти в 4 раза!
Давайте посмотрим, какие запросы у нас выполняются во время загрузки страницы. Для этого в коде \MyProject\Services\Db::query добавим var_dump:
public function query(string $sql, array $params = [], string $className = 'stdClass'): ?array
{
var_dump($sql);Обновим страничку и увидим, что у нас выполнилось 2 запроса:

Так как при загрузке первой страницы запрос:
SELECT COUNT(*) AS cnt FROM articles; остаётся неизменным, мы понимаем, что в случае последней страницы работу существенно замедляет второй запрос:
SELECT * FROM `articles` ORDER BY id DESC LIMIT 5 OFFSET 999995;В случае загрузки первой страницы он будет выглядеть следующим образом:
SELECT * FROM `articles` ORDER BY id DESC LIMIT 5 OFFSET 0;Давайте сделаем ANALYZE (я использую mariadb, для mysql будет EXPLAIN ANALYZE) для обоих запросов.
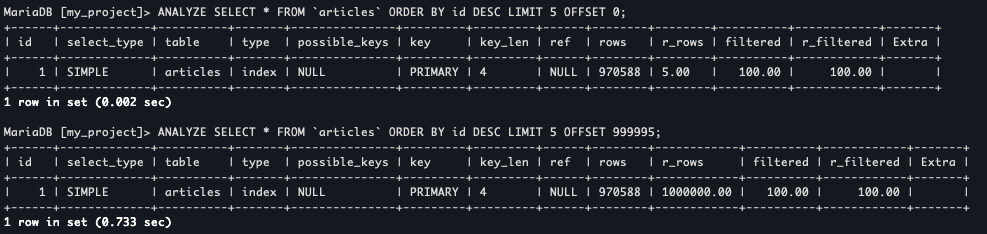
Как видим, в случае первой страницы базке пришлось пройти 5 строк (r_rows), а в случае последней страницы 1000000 строк! Дело в том, что OFFSET N работает таким образом, что он вычитывает строки, подходящие под условие запроса до тех пор, пока не дойдёт до N-ой строки. Всё что до N будет пропущено, а далее будут выгружены строки после N-ой, до необходимого значения LIMIT. То есть, к примеру, в нашем случае при получении 200й страницы блога база будет прогонять при запросе следующие строки:
Id -> 1000000
Id -> 999999
…// Тут ещё очень много строк
Id -> 6
Id -> 5 // Все строки, что выше, пропускаем. Их там 999995. Начиная с этой выгребаем ещё X строк, где X – значение, указанное в LIMIT (в нашем случае = 5)
Id -> 4
Id -> 3
Id -> 2
Id -> 1 // Выгрузили 5 строк, на этом всёКак видим, базе пришлось сделать много лишней работы. Так уж работает OFFSET. Какие есть альтернативы? Давайте для начала посмотрим на предпоследнюю страницу блога.
http://myproject.loc/199999
Как мы можем получить следующие 5 записей, чтобы сформировать следующую страницу?
Зная, что текущая страница заканчивается на id = 6, нам можно получить следующие 5 записей, сформировав следующий запрос:
SELECT * FROM `articles` WHERE id < 6 ORDER BY id DESC LIMIT 5;
Как видим, результаты выполнения запросов совпадают. Однако, время их выполнения существенно отличается. Давайте проанализируем запрос.
ANALYZE SELECT * FROM `articles` WHERE id < 6 ORDER BY id DESC LIMIT 5;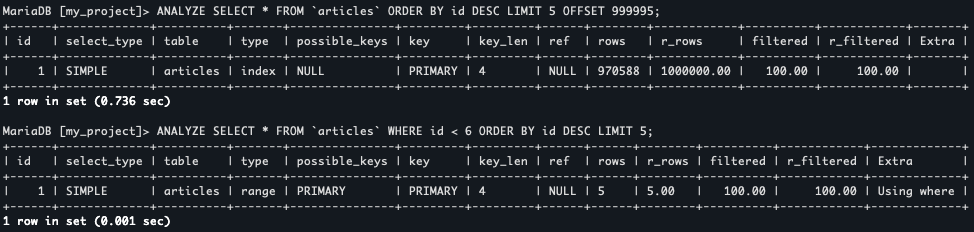
Как мы видим, теперь базе пришлось считать всего 5 строк из таблицы. Это произошло благодаря использованию индекса по полю id. Мы просто отфильтровали ненужные нам строки и начиная с нужной получили первые 5.
Теперь давайте напишем запрос, который позволит получить записи с предыдущей страницы. Для этого нам нужно получить 5 статей, которые идут до первой статьи на текущей странице. В нашем случае это записи с id > 10:
SELECT * FROM `articles` WHERE id > 10 ORDER BY id ASC LIMIT 5;
Как видим, запрос тоже выполнился быстро. Давайте проанализируем и его.

Видим r_rows = 5, всё в порядке.
Однако, как вы могли заметить, записи отсортированы не в том порядке, в котором они должны выдаваться в блоге. Давайте исправим это.
SELECT * FROM (SELECT * FROM `articles` WHERE id > 10 ORDER BY id ASC LIMIT 5) as articles ORDER BY id DESC;
Теперь всё в порядке. Это можно сделать и средствами PHP, вызвав функцию array_reverse() после получения результатов из базы. Как вы это сделаете – не так важно, это дешевая операция, относительно той, что была, когда мы работали через OFFSET.
Что-ж, остаётся только запрограммировать логику. Вместо url-ов вида myproject.loc/777 нам нужно сделать 2 поддерживаемых урла типа:
- myproject.loc/before/777
- myproject.loc/after/777
для получения страницы статей до id=777 и после id=777, соответственно.
Добавляем в контроллер 2 новых экшена:
\MyProject\Controllers\MainController
public function before(int $id)
{
}
public function after(int $id)
{
}и соответствующие им роуты:
myproject.loc/src/routes.php
'~^before/(\d+)$~' => [\MyProject\Controllers\MainController::class, 'before'],
'~^after/(\d+)$~' => [\MyProject\Controllers\MainController::class, 'after'],Добавим в сущность статьи метод для получения статей для страницы до заданного id:
\MyProject\Models\Articles\Article
/**
* @return Article[]
*/
public static function getPageBefore(int $id, int $limit): array
{
$db = Db::getInstance();
$sql = sprintf('SELECT * FROM (SELECT * FROM '.self::getTableName().' WHERE id > :id ORDER BY id ASC LIMIT %d) as articles ORDER BY id DESC;', $limit);
return $db->query($sql, ['id' => $id], self::class);
}И аналогичный метод для получения статей после заданного id:
/**
* @return Article[]
*/
public static function getPageAfter(int $id, int $limit): array
{
$db = Db::getInstance();
$sql = sprintf('SELECT * FROM '.self::getTableName().' WHERE id < :id ORDER BY id DESC LIMIT %d;', $limit);
return $db->query($sql, ['id' => $id], self::class);
}Помимо этого, нам также понадобятся ещё 2 метода, которые позволят узнать, есть ли после какого-то (или до какого-то) id ещё записи. Это потребуется, чтобы узнать, есть ли следующая или предыдущая страница, чтобы нарисовать ссылки.
public static function hasNextPage(int $pageLastId): bool
{
$db = Db::getInstance();
$sql = 'SELECT id FROM '.self::getTableName().' WHERE id < :id LIMIT 1;';
$result = $db->query($sql, ['id' => $pageLastId]);
return !empty($result);
}
public static function hasPreviousPage(int $pageFirstId): bool
{
$db = Db::getInstance();
$sql = 'SELECT id FROM '.self::getTableName().' WHERE id > :id LIMIT 1;';
$result = $db->query($sql, ['id' => $pageFirstId]);
return !empty($result);
}Осталось написать логику в экшенах контроллера.
public function before(int $id)
{
$this->page(Article::getPageBefore($id, 5));
}
public function after(int $id)
{
$this->page(Article::getPageAfter($id, 5));
}
private function page(array $articles)
{
if ($articles === []) {
throw new NotFoundException();
}
$firstID = $articles[0]->getId();
$lastID = $articles[count($articles)-1]->getId();
$this->view->renderHtml('main/main.php', [
'articles' => $articles,
'previousPageLink' => Article::hasPreviousPage($firstID) ? '/before/' . $firstID : null,
'nextPageLink' => Article::hasNextPage($lastID) ? '/after/' . $lastID : null,
]);
}Пробуем зайти на страницу, на которой будут записи до id=20: http://myproject.loc/before/20

Обратите внимание на время генерации страницы. 0.017035 секунды! То есть произошло ускорение в 1,045724/0,017035 = 61,4 раза! Согласитесь, неплохо!
Осталось сделать главную страницу, которая будет рисоваться при запросе http://myproject.loc/
Для этого нам нужно получить id последней статьи, прибавить к нему 1, и вызвать экшен after() с полученным значением.
Добавим в сущность метод для получения последнего id.
\MyProject\Models\Articles\Article
public static function getLastID(): ?int
{
$db = Db::getInstance();
$sql = 'SELECT id FROM '.self::getTableName().' ORDER BY id DESC LIMIT 1;';
$result = $db->query($sql);
return !empty($result) ? $result[0]->id : null;
}И дополним наш контроллер:
public function main()
{
$lastID = Article::getLastID();
if ($lastID === null) {
throw new NotFoundException();
}
$this->after($lastID + 1);
}Проверяем главную страницу http://myproject.loc/
Всё в порядке. Страница сгенерировалась за 0.010365.
Код, расположенный в сущности Article легко выносится в класс ActiveRecordEntity, и масштабируется на все другие возможные модели.
Дифф с изменениями вы найдете здесь - https://github.com/ivashkevitch/oop-v-php-prodvinutyj-kurs/pull/2/files
А, ну и кстати, осталась ещё пара мест, где можно сэкономить. Во-первых, если мы знаем (а мы знаем), что id статей начинается с 1, то можно избавиться от лишнего похода в базу при проверке наличия следующей страницы:
\MyProject\Controllers\MainController
private function page(array $articles)
{
...
'nextPageLink' => $lastID > 1 ? '/after/' . $lastID : null,
...
}А ещё можно закешировать id последней добавленной статьи, и избежать еще одного запроса в базу. Я сделал файловый кеш прямо в контроллере. Так делать не надо :) Это просто для быстрой демонстрации. Выносите такое куда-нибудь на уровень доменного сервиса. Там же при добавлении новых статей сбрасывайте/обновляйте кеш.
...
$this->view->renderHtml('main/main.php', [
'articles' => $articles,
'previousPageLink' => $firstID < $this->getLastArticleID() ? '/before/' . $firstID : null,
'nextPageLink' => $lastID > 1 ? '/after/' . $lastID : null,
]);
}
private function getLastArticleID(): int
{
$cacheFile = __DIR__ . '/../../../cache/last_article_id';
$value_from_cache = file_get_contents($cacheFile);
if (!empty($value_from_cache)) {
return (int)$value_from_cache;
}
$lastID = Article::getLastID();
file_put_contents($cacheFile, $lastID);
return $lastID;
}После этого остаётся единственный запрос в базу, а время генерации страницы уменьшается до 0.005457 секунды.
На этом всё, спасибо что дочитали :)

Комментарии