Выполнение запросов в MySQL
Итак, разобрались со структурой таблиц. Теперь давайте поработаем с данными в таблицах.
Добавление данных в таблицу
Для добавления данных используется запрос INSERT. Синтаксис:
INSERT INTO имя_таблицы ([столбцы]) VALUES ([значения]);Давайте вставим в нашу таблицу users несколько пользователей:
INSERT INTO users (email, name) VALUES('x1@php.zone', 'Иван');
INSERT INTO users (email, name) VALUES('x2@php.zone', 'Ольга');
INSERT INTO users (email, name) VALUES('x3@php.zone', 'Александр');
INSERT INTO users (email, name) VALUES('x4@php.zone', 'Елена');
INSERT INTO users (email, name) VALUES('x5@php.zone', 'Ольга');
INSERT INTO users (email, name) VALUES('x6@php.zone', 'Матвей');
INSERT INTO users (email, name) VALUES('x7@php.zone', 'Иван');
INSERT INTO users (email, name) VALUES('x8@php.zone', 'Пётр');
INSERT INTO users (email, name) VALUES('x9@php.zone', 'Иван');После этого мы увидим информацию об успешно выполненных запросах на добавление записей

Запрос данных из таблицы
Данные из таблиц получают с помощью запроса SELECT.
Самый простой запрос, позволяющий просмотреть записи таблицы, выглядит так:
SELECT * FROM users;Звездочка означает взять все столбцы таблицы.

Если нам не нужен в результате id, можно написать так:
SELECT name, email FROM users;
LIMIT и OFFSET
Для ограничения выдачи используется ключевое слово LIMIT. Выведем только первые 2 записи.
SELECT * FROM users LIMIT 2;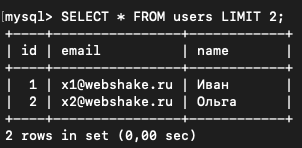
Для того, чтобы выполнить смещение на 2 записи, нужно использовать ключевое слово OFFSET.
SELECT * FROM users LIMIT 2 OFFSET 2;
Таким образом мы пропустили 2 первые записи и ограничили выборку двумя следующими записями.
Чтобы вывести следующие 2 нужно увеличить смещение еще на 2, изменив значение OFFSET:
SELECT * FROM users LIMIT 2 OFFSET 4;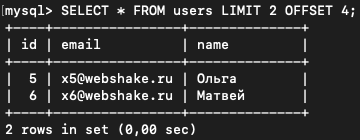
С помощью OFFSET и LIMIT реализуется пагинация записей.
DISTINCT
Давайте сделаем запрос только с именами:
SELECT name FROM users;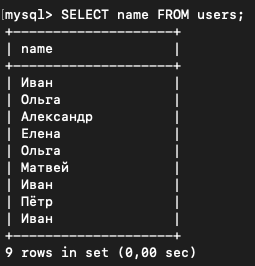
Сейчас мы видим, что в таблице у нас несколько повторяющихся имён: Иван и Ольга.
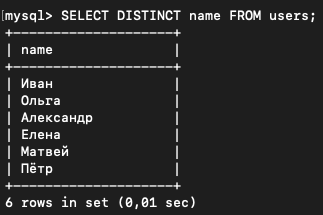
Чтобы оставить только разные имена в результате запроса используется ключевое слово DISTINCT (переводится с английского как "индивидуальный", "отдельный").
SELECT DISTINCT name FROM users;Результат:
Условия в запросах
Если нужно отфильтровать значения по какому-то условию, используется WHERE. Например:
SELECT * FROM users WHERE name = "Иван";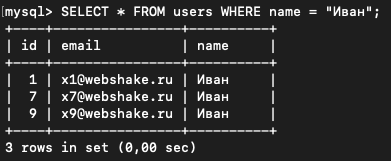
Используя операторы AND и OR можно задать несколько условий.
SELECT * FROM users WHERE name = "Иван" OR name = "Ольга";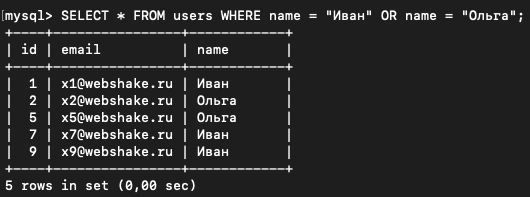
С помощью ключевого слова NOT можно инвертировать условие:
SELECT * FROM users WHERE NOT name = "Ольга";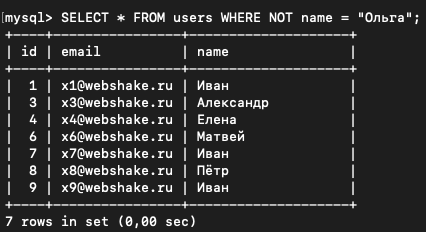
Сортировка
Для сортировки значений используется ключевое слово ORDER BY. По умолчанию ORDER BY делает сортировку в порядке возрастания (ASC).
SELECT * FROM users ORDER by name;Если нужно отсортировать в обратном порядке нужно добавить ключевое слово DESC:
SELECT * FROM users ORDER by name DESC;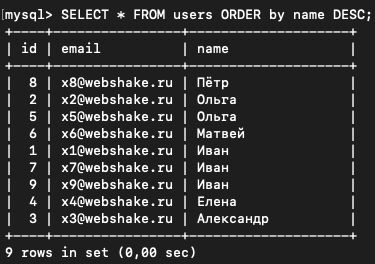
Группировка
Результаты запроса можно сгруппировать по одному или нескольким столбцам. В итоге строки, содержащие одинаковые по группируемым столбцам значения, как бы "схлопнутся" в агрегированные значения. Пример такого запроса:
SELECT id, email, name FROM users GROUP BY name;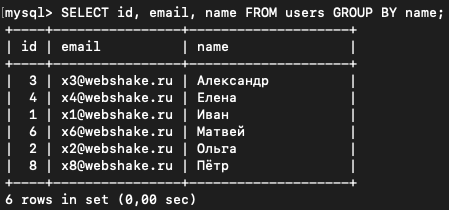
В результате мы видим, что строки с одинаковыми именами схлопнулись в одну. Но вопрос в том, почему, например, имени "Иван" в выдаче соответствуют именно id=1 и email=x1@php.zone. Ответ: это просто случайность! Если мы видим перед собой "сгруппированную" строку, рядом с которой выводятся поля, по которым группировка не выполнялась, то в эти поля попадет случайное значение одной из сгруппированных строк.
То есть вот у нас было 3 строки с именем "Иван".
| 1 | x1@php.zone | Иван |
| 7 | x7@php.zone | Иван |
| 9 | x9@php.zone | Иван |После группировки по полю "name" в результате нашего запроса в столбце name всегда будет "Иван". А вот по остальным столбцам, по которым группировка не производилась, будет случайное значение одной из этих строк. Это очень важно запомнить, что это значение случайное, и в другой раз там может быть уже другое.
Агрегирующие функции
Вместе с использованием GROUP BY над сгруппированными данными можно выполнять агрегирующие функции. Одна из самых часто используемых функций - COUNT, она считает число записей.
Давайте применим её к нашей выдаче чтобы узнать, какие имена сколько раз встречаются.
SELECT name, COUNT(name) FROM users GROUP BY name;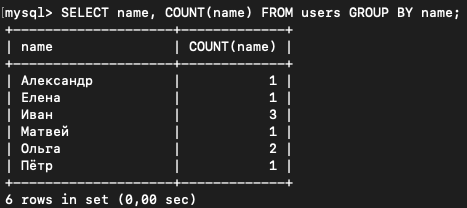
Агрегирующие функции можно также использовать внутри ORDER BY. К примеру, можно отсортировать имена по количеству вхождений по убыванию.
SELECT name, COUNT(name) FROM users GROUP BY name ORDER BY COUNT(name) DESC;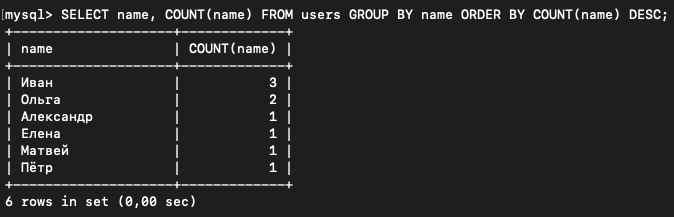
Другие наиболее часто используемые агрегирующие функции:
| Функция | Действие, выполняемое над сгруппированными данными |
|---|---|
| COUNT() | Подсчет количества строк |
| SUM() | Подсчет суммы значений |
| AVG() | Вычисление среднего значения |
| MIN() | Определение минимального значения |
| MAX() | Определение максимального значения |
HAVING
А если мы захотим вывести только имена, встречающиеся в базе более одного раза? Давайте попробуем сделать это с помощью WHERE:
SELECT name, COUNT(name) FROM users WHERE COUNT(name)>1 GROUP BY name DESC;В ответ мы получим ошибку:
Invalid use of group function
Так произошло потому что группировка выполняется после WHERE, таким образом агрегирующей функции внутри WHERE просто ещё не с чем работать, отсюда и ошибка.
Как нам быть? К счастью, для фильтрации строк ПОСЛЕ выполнения группировки есть ключевое слово HAVING.
Теперь сделаем то, что хотели.
SELECT name, COUNT(name) FROM users GROUP BY name HAVING COUNT(name)>1;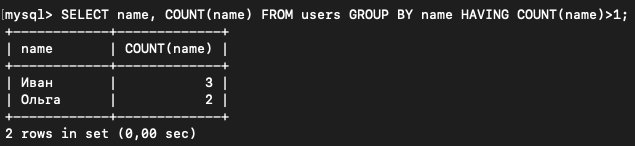
Поиск по шаблону
Чтобы искать данные по шаблону нужно использовать ключевое слово LIKE. Оно используется в связке со специальными символами - % и _. % является шаблоном для ни одного, одного или нескольких любых символов. _ представляет собой шаблон для одного любого символа. Давайте лучше пример. Найдем все записи, у которых в значении поля name есть буква л:
SELECT * FROM users WHERE name LIKE "%л%";
Или начинающиеся с любой буквы, дальше имеющие сочетание "ле", и заканчивающиеся как угодно:
SELECT * FROM users WHERE name LIKE "_ле%";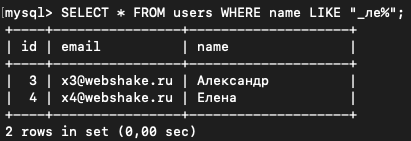
На этом с выборкой значений пока остановимся. Хотя это еще не все возможности, лучше будет сначала закрепить эти основы. А пока рассмотрим запросы для изменения данных в таблицах.
Изменение данных
Изменить данные в таблице можно с помощью запроса UPDATE. В запросе UPDATE так же можно использовать условия используя ключевое слово WHERE. А еще в нем присутствует слово SET, с помощью которого определяются новые значения.
Обновим почту у пользователя с id = 2:
UPDATE users SET email = "new@php.zone" WHERE id = 2;
Запросим теперь эту запись:
SELECT * FROM users WHERE id = 2;
Как видим, всё успешно обновилось
Удаление данных из базы
Для удаления используется запрос DELETE. И тут та же тема с WHERE:
DELETE FROM users WHERE id = 2;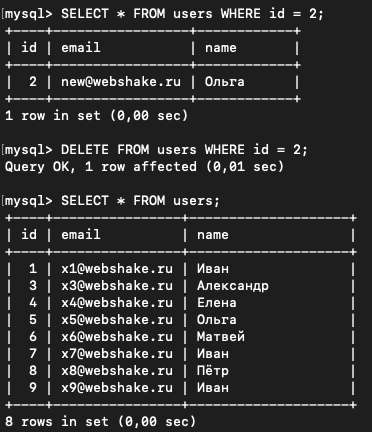
Мы рассмотрели самые базовые запросы, однако этого уже достаточно для большинства простых задач. В дальнейших уроках будут более интересные и сложные запросы. А пока - закрепите материал домашним заданием.

Комментарии